While working at a previous job a while back, I noticed that the code we were writing was complex. After some thought, I realized that we had monstrous abstractions that were hard to maintain, so I did a little research and shared a talk with my coworkers. I also wrote this article I'm sharing with you today.
Storytime.
Let's start with a short story: Andrew, a developer, is commissioned with a new feature. He starts coding it and soon realizes that he is duplicating some logic in the codebase, so he decides to create an abstraction and replace all code instances with the new abstraction. He completes his task and merges the code back to the main branch.
Sometime after, Barbara, another engineer, needs to implement a new feature. She starts doing so and suddenly realizes that there is an abstraction in the codebase (the one created by Andrew!) that adjusts almost perfectly to the thing she needs to implement. So instead of repeating the code, she adds a new parameter to the abstraction and adds a new conditional inside it to handle the differences. This same process happens with Carla, Dorothy, Elton, and many others that came after them.
At this point, you get into the equation. As part of your current sprint, you need to implement a new feature, and you realize that you will need to update the abstraction code. But there is a problem: the abstraction has undergone so many changes that it no longer makes sense. It's a giant piece of code that is hard to understand and almost impossible to change.
Does this sound familiar to you? Have you ever faced this situation? I certainly have!
Why do we do it?
The first question that comes to my mind is why we do this. Why do we end up in this spot? And to those questions, I can think of a couple of answers:
We have learned from our mentors that it is good.
When we start coding, one of the first things we learn is the concept of functions or procedures, and with time, we will acquire even more sophisticated mechanisms like modules or classes. We have learned that creating these units to factor repeated code is good as it reduces complexity and the maintenance burden. Later on, we learned the DRY (Don't repeat yourself) principle, and that's the last nail in the coffin.
These are all simple rules, easy to understand, and they all make sense to us, but can we be sure they are always valid?
A giant abstraction covering multiple cases can lead to spaghetti code, increase the maintenance cost, and increase the number of bugs. The spaghetti code is a consequence of everything being coupled to the abstraction, whose size tends to grow, making it harder to maintain than a smaller one. It is also hard to change because you need to consider every usage of it.
As Sandi Metz said, we should prefer duplication over the wrong abstraction.
We feel pleasure when we abstract code.
As a consequence of the learnings we mentioned above, it may happen that creating these abstractions makes us feel good. We have fulfilled an ancient commandment: this brings peace to our minds and joy to our hearts.
But creating abstractions and craving for this feeling must not be our end goal. As Cheng Lou mentioned in his talk "On the Spectrum of Abstraction": for computer scientists, abstraction is an end, but for software engineers, abstractions are just a means to an end.
We think it will be helpful in the future.
A typical scenario is that when developing a feature, an engineer creates a function or component used only in one place. This unit of code is only used by that feature, but it's implemented so that it's independent of it. For that reason, the developer thinks that it may be helpful in the future, so they decide to put it in a folder named common/shared/utils and make it available for the complete codebase.
But we don't know if this will be useful in the future. We don't know if we will use it in any other part of the codebase at all: this is a hasty generalization, and we have created a new unnecessary abstraction.
How can we do it better?
Does all of this mean that abstractions are wrong and we should avoid them? Not at all! They are tremendously helpful when done right. So I would like to present you with some principles to guide us when creating an abstraction. These principles should help us answer two simple questions: when and what.
When? The rule of three.
As defined by Wikipedia:
Rule of three ("Three strikes and you refactor") is a code refactoring rule of thumb to decide when similar pieces of code should be refactored to avoid duplication. It states that two instances of similar code don't require refactoring, but when similar code is used three times, it should be extracted into a new procedure. The rule was popularized by Martin Fowler in Refactoring and attributed to Don Roberts.
Even though this rule provides a threshold for when we should create an abstraction (three repetitions), that's not the important part. We should learn from this rule that some amount of duplication is acceptable until we understand which is the best abstraction for our code.
What? The rule of least power.
In 2006 Tim Berners-Lee wrote "The Rule of Least Power". In this article, Berners-Lee states the following:
When designing computer systems, one is often faced with a choice between using a more or less powerful language for publishing information, for expressing constraints, or for solving some problem. This finding explores tradeoffs relating the choice of language to reusability of information. The "Rule of Least Power" suggests choosing the least powerful language suitable for a given purpose.
Even though the author is talking about computer languages, we can easily translate this principle to software engineering and the design of abstractions. More powerful abstraction allows us to do more with less code, while a least powerful abstraction requires more work to get to the same results. On the other hand, the more powerful the abstraction, the harder it is to adjust it to different cases.
For example: imagine you want to implement the following list:
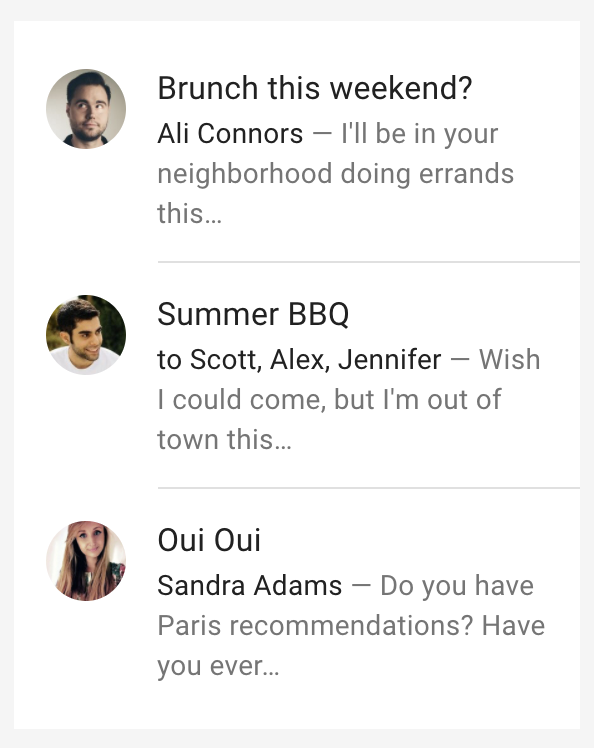
You could create a single powerful component named MagicList that receives all its data through parameters or props and renders this exact list. But then, if you happen to need a list without an avatar or secondary text, you need to keep adding parameters and conditionals to handle those cases, turning your component into a monster.
Alternatively, you could implement less powerful abstractions like List and ListItem and use them to construct your component.
The bottom line here is that the less powerful the abstraction, the more chances you have of reusing it organically.
Conclusions
Picking the right abstraction is difficult, but it's not impossible. If we improve our ability to do so, we will be able to craft high-quality software. Hopefully, the rules discussed above will be of help to you.
Additional material / useful links
The wrong abstraction, by Sandi Metz.
The wet codebase, by Dan Abramov.
Minimal API Surface, by Sebastian Markbage.
On the Spectrum of Abstraction, by Cheng Lou.
AHA Programming, by Kent C. Dodds.
The Rule of Least Power, by Tim Berners-Lee.
Cover Image: "Blueprints" by Sam Howzit is licensed under CC BY 2.0.